Introduction
I’ve had this urge to go down the bare metal of LLMs, and channeling that with catching up on a some podcasts, seminars etc. But what better to quench this thirst than do a Stanford Online class, that popped on my timeline like this-
!(https://x.com/JeffDean/status/1937676323172024808)
And so this series is about going through course and coming through on the other side an LLM jedi.
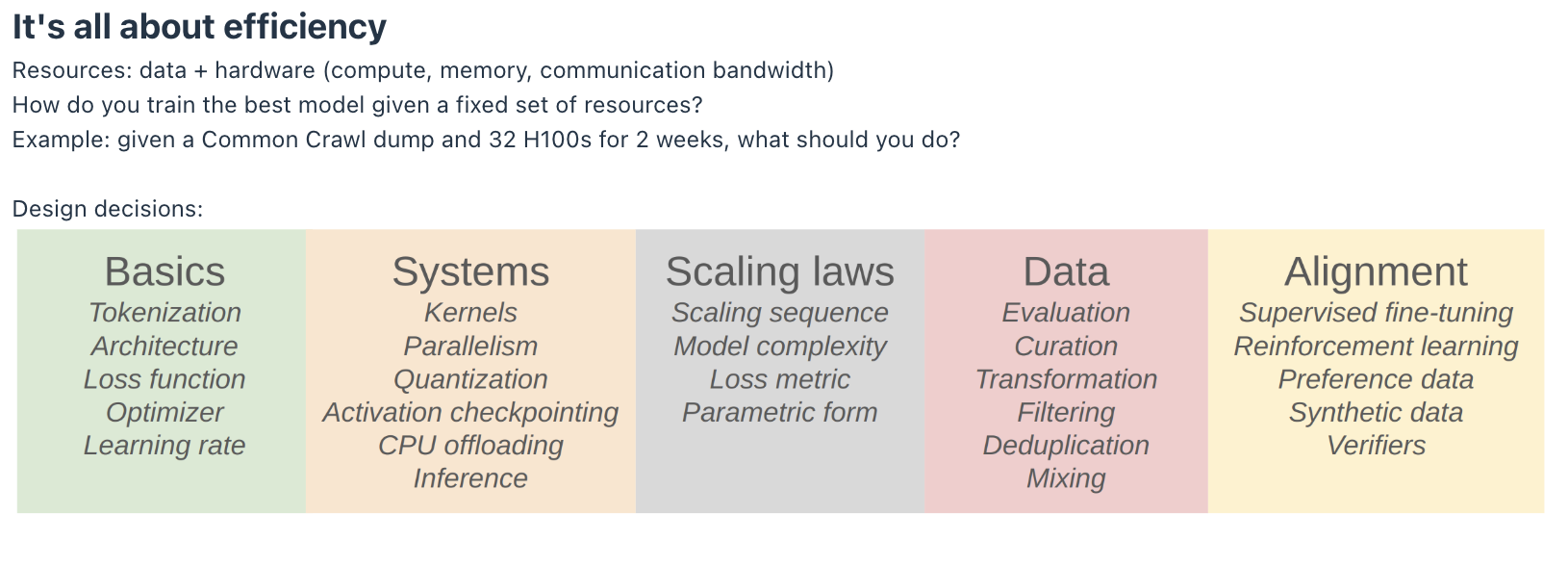
The course is organized into these 5 pillars:
- Basics
- Systems
- Scaling laws
- Data
- Alignment
The Basics
- Tokenizer - convert between strings and sequences of integers, the most commonly used today is the Byte-pair encoder.
- Architecture - based on Transformer, the backbone of all frontier models. Comprises of Attention and the MLP pieces. The core architecture is unchanged but we have had many breakthroughs across
- activation functions - ReLU, SwiGLU
- positional embeddings - sinusoidal, RoPE
- normlization - LayerNorm, RMSNorm
- placement of normalization
- MLP - dense, MOE
- Attention - full, sliding window, linear
- lower-dimentional attention- group-query (GQA), multi-head latent attention (MLA)
- Trainig
- Optimizer - Adam
- learning rate schedule
- batch size - critical batch size
- regularization- drop out, weight decay
- hyperparameters (no of heads, hidden dimentions) - grid search
Systems
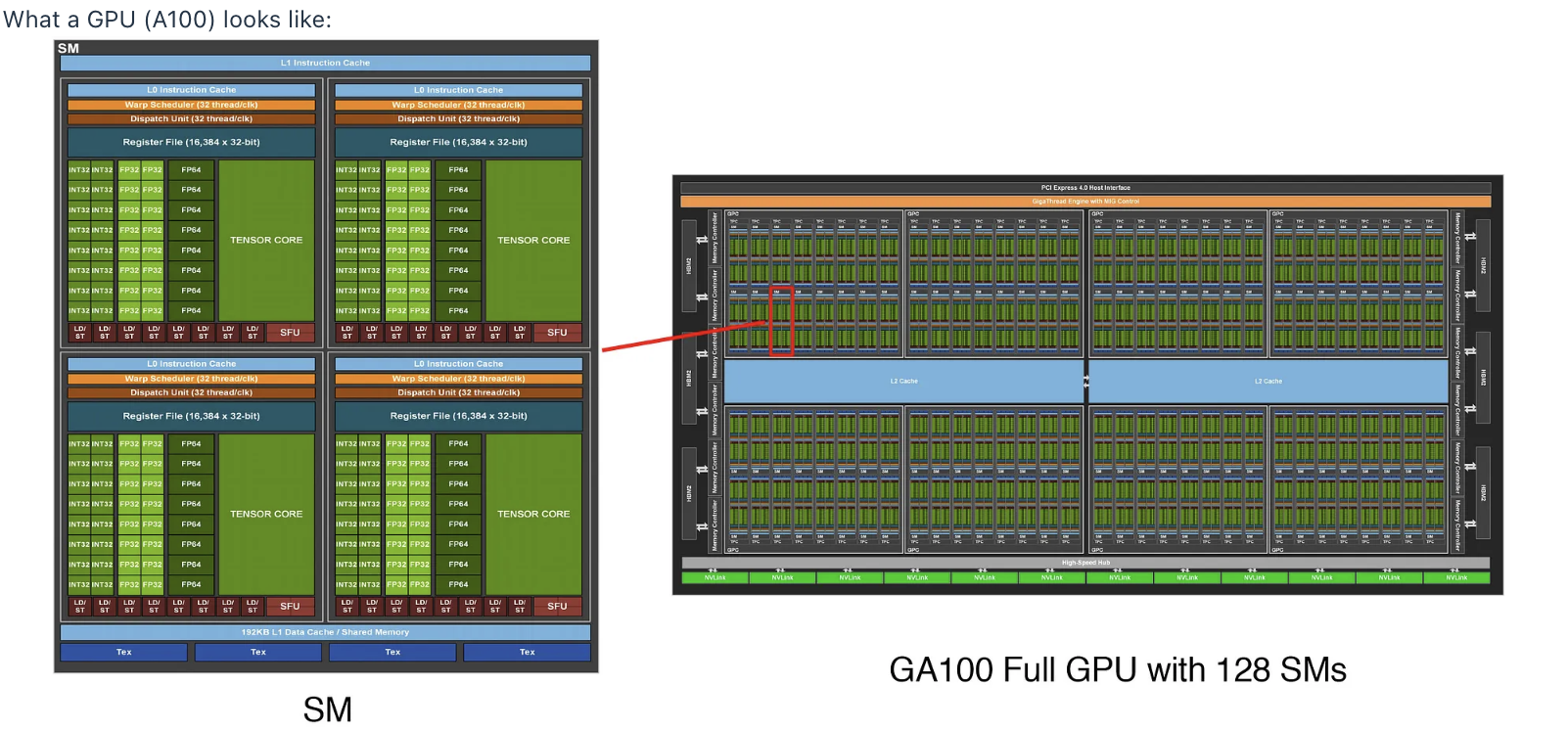
A typical A100 looks like this- with an array of units doing FLOPs. The compute happens on each of the cells on the right, but the data lives somewhere else. The goal is to organize computation to maximize utilization of GPUs by minimizing data movement
Parallelism - when we have multiple GPUs
- data movement between GPUs is even slower, principle is ‘minimize data movement’
- Shard paramters, activations, gradients,, optimizer states across GPUs.
- split computation - data/tensor/pipeline/sequence parallelism
Infernence
- inference costs scale with usage (for each use of model) and eclipses training cost (one time). Very important.
- 2 phases - prefill and decode
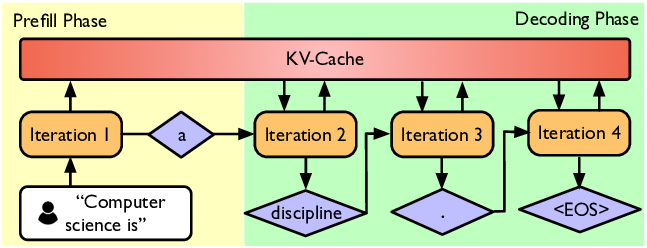
- Prefill take a prompt and run it through a model and get some activations. All tokens are given (similar to training), so processed at same time. Compute bound.
- Decode - generate one token at a time, hard to saturate GPUs and becomes memory bound (as we’re constantly moving data around).
- Methods to speed up decoding
- use cheaper model - via model pruning, quantization, distillalation
- Speculative decoing - use cheaper “draft” model to generate multiple tokens, then use full model to score in parallel (exact decoding)
Scaling Laws
- principle is do experiments at small scale, predict hyperparametrs/loss at large scae
- fundamental & well-studied question - given a FLOPs budget, tradeoff between bigger model ($N$) vs more data ($D$)
- Compute-optimal scaling laws - “Chinchilla Optimal” - for every compute budget (#-FLOPs), you can vary #-params and see u-shaped loss curve. the optimal param count scales linearly with FLOPs.
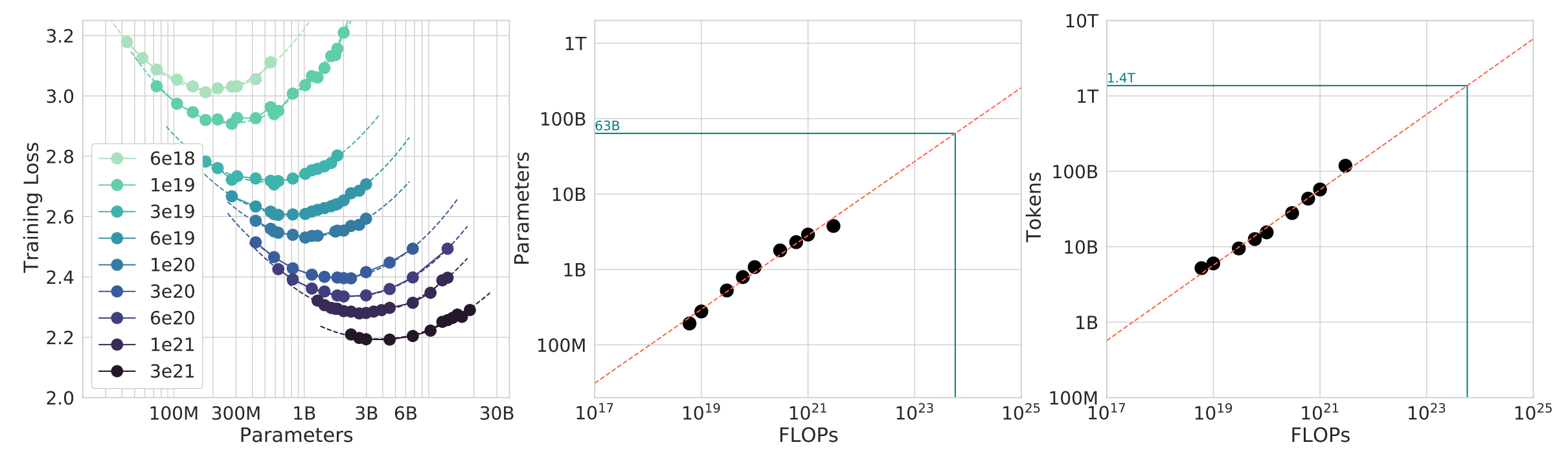
TLDR - to train a model of size N, use 20xN training tokens (1.4B param model needs training on 28N tokens)
Data
Important steps- Evaluation, curation, processing
Alignment
What we have after training is a base model - alignment makes it useful.
- follow instructions
- style - sass, bullets, verbosity
- safety
2 phases
SFT - supervised training on prompt-response pairs to maximize p(response|prompt)
Learning from feedback - improve model without more expensive heavy annotation
- preference data - user provides preferences
- verifiers - code, match can have formal verifier or learned verifier like LLM-as-judge
RL
- PPO - Proximal Policy Optimization - if we have verifier data
- DPO - Direct Policy Optimizaiton - if we have preference data
- GRPO - Group Relative Preference Optimization - simplifies PPO by removing value function (deepeek)
Ultimately, efficiency drives design decisions.