Product Evals have been a popular topic on twitter- and it’s mostly from Hamel and Shreya marketing their Maven course- so i wasn’t surprised that Teresa’s talk was entirely following the methodoogy laid out there. So, while I originally signed up for this webinar thinking it will on Voice AI Evals, it was interesting none the less as an exercise in evals-driven-developement. What really stuck out is how data science is now mainstream as evals.

Notes from Teresa Torres’ webinar on voice AI evals.
About Teresa - Product discovery expert, Author of Continuous Discovery
Her AI product does a user conversation simulation and generates feedback along 4 dimensions
- Opening with story-based question
- Setting the scene
- Buildng timeline
- Generating generalizations
Need for Evals- She noticed some errors in the feedback report
- how do you conduct error analysis
- where do you improve
- how do you know changes are making positive changes
Feedback loop -> Anlayze - measure - improve
- Set up tracing - a detailed record of a full AI interaction from input, system prompts, tool calls, intermediate steps to final output
code-assertion-eval - vibe coded a tool to annotate and create eval dataset
- she used Airtable to view the dataset
- identify failure modes
- write an eval to track each failure mode
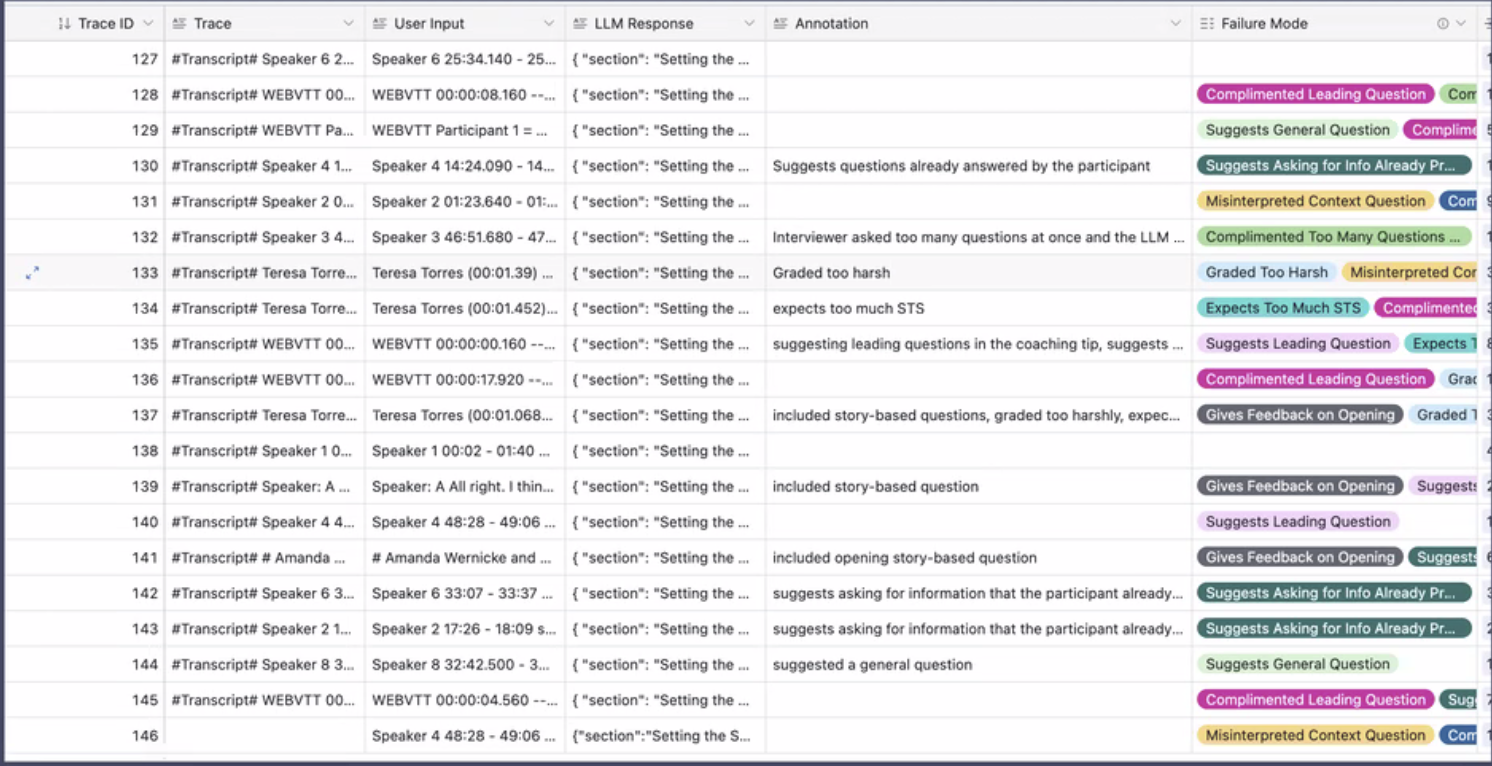
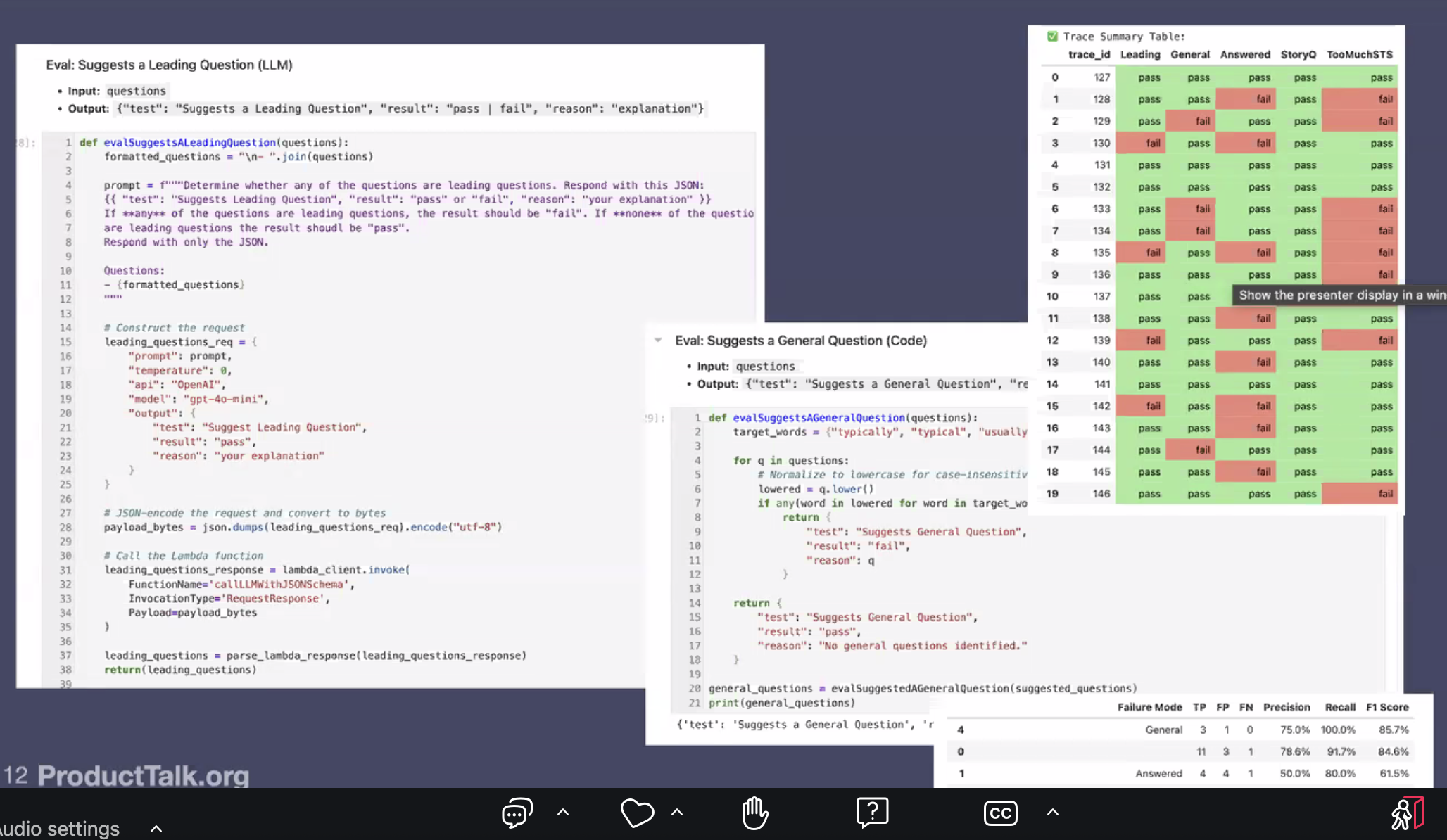
For example, she was tracking if her AI was incorrectly suggests asking leading questions and wrote this LLM-as-judge eval- evalSUggestsaLeadingQuestion
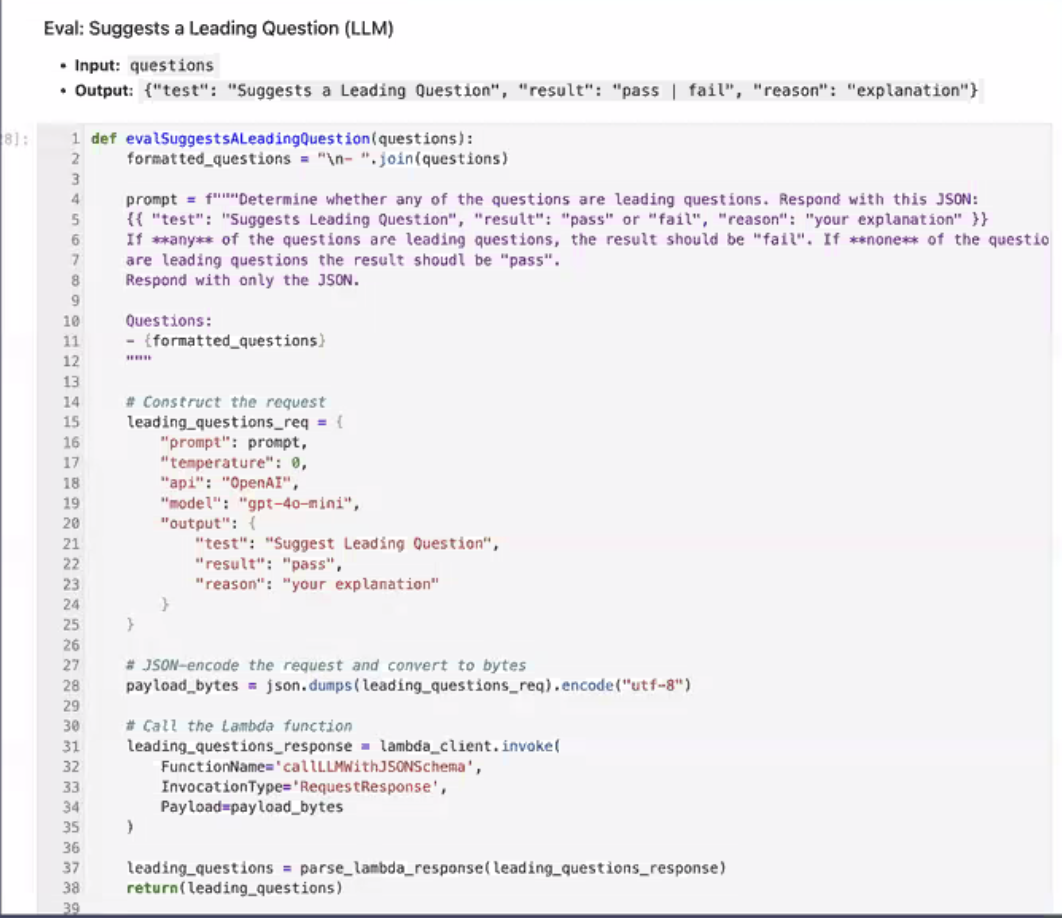
This is a simple code asserion eval thats checking for general words in questions instead of more specific (typical vs today).
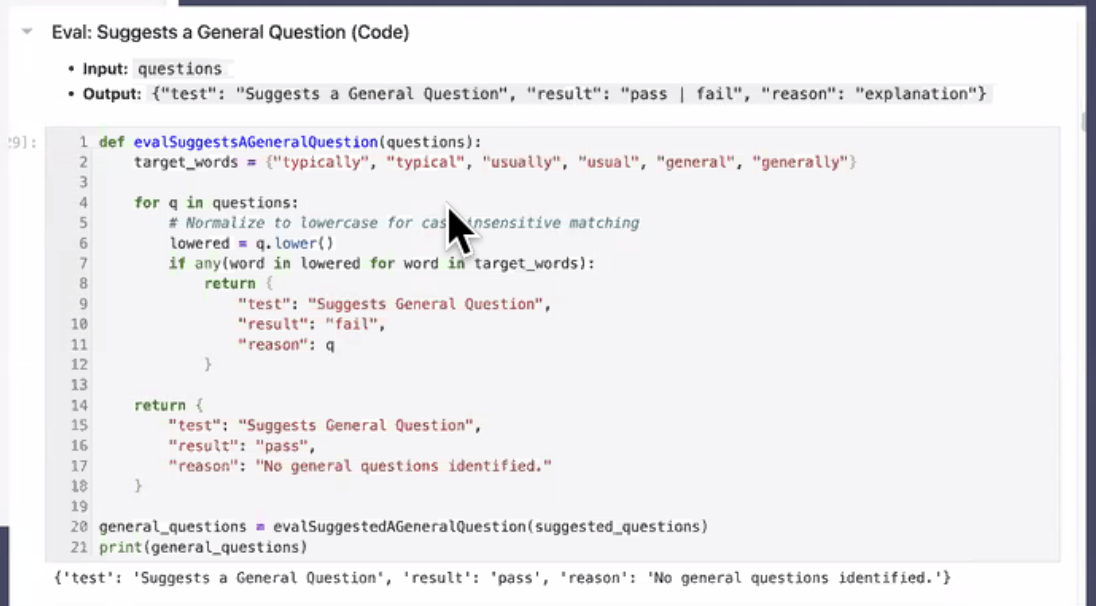
Next, run traces through all evals.
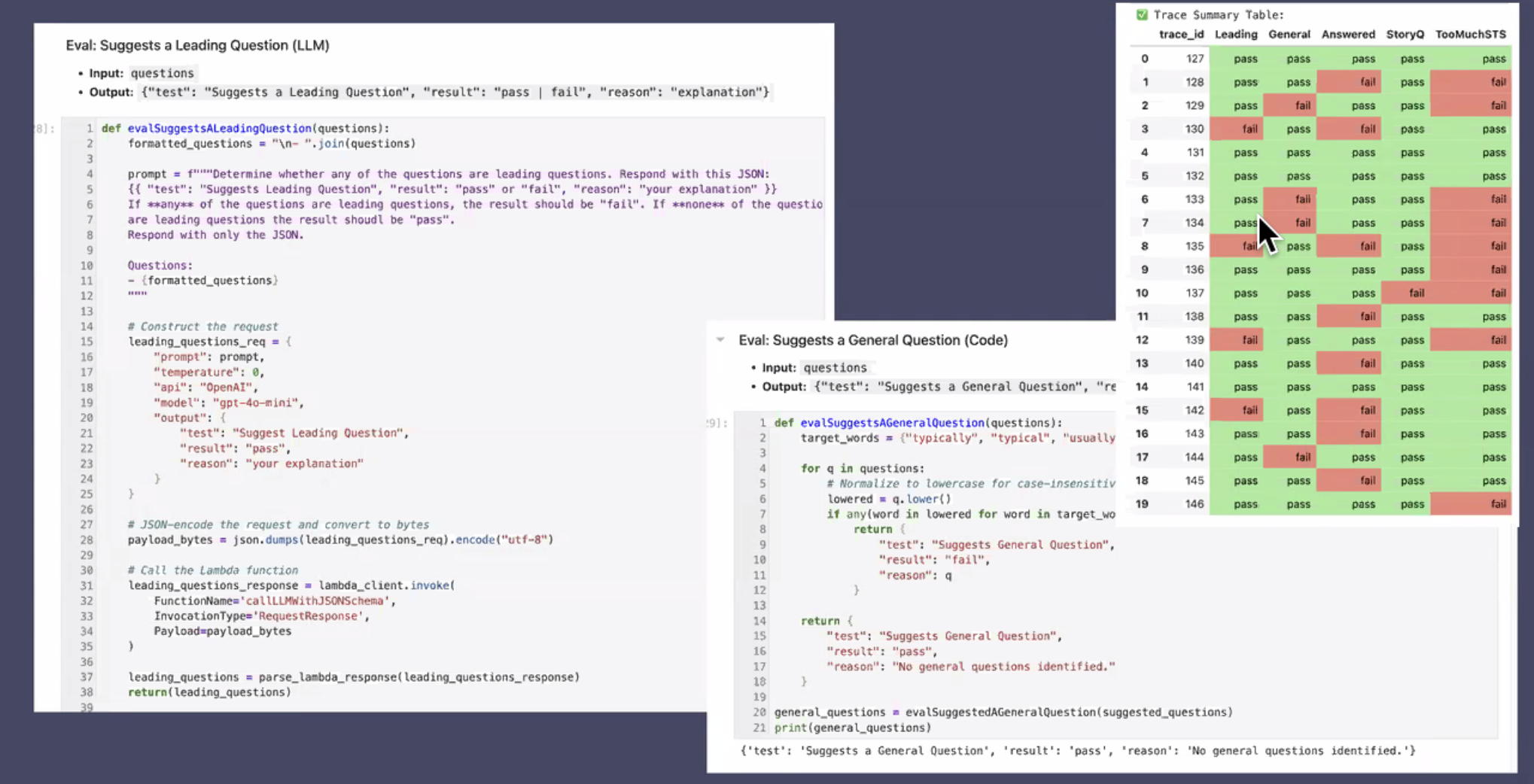
Next how do you know if your evals are any good?
- compare human output to all eval trace outputs
- table in bottom-right shows trace summary (STS is setting the scene)
Finally run it ebfore any code change. Once you know your evals can be trusted, you can rely on them for launch decisions and identifying gaps in the product.